I've just returned from presenting at CppCon 2024. Links below: [Presentation Slides] [YouTube CppCon 2024 presentation]
I've started a new website which is dedicated to designing and implementing professional grade software architecture using modern C++. The intention is to write a series of articles which build components step by step coupled with working libraries, explanations, analysis etc. And then build actual software products using these libraries.
There's a lot of work to do but I've started it with one of the basics of good architecture - threading. Admittedly the threading techniques that I started with are extremely advanced and is a new technique but its far better than what exists. I made the decision to start with something strong, but future topics will include things which are not so 'deep end of the pool' as well.
First articles deal with Work Contracts: A high performance, lock free, asynchronous task management system The accompanying github repo for all of the projects for Buiding C+ is here github.com/buildingcpp.
Sometimes I get mail. Here is the most wonderful mail that I've even received. I found it on my desk next to my keyboard.

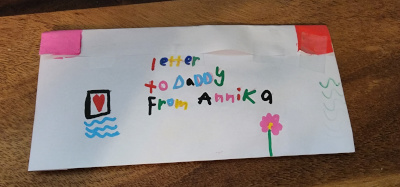

I recently had to tear out and rebuild a kitchen. I do some wood working from time to time and I was really pleased with how my cabinetry skills worked out here. I built all of this in the house my father left me when he passed away. It's a shame that I waited until he was gone to do this work. I think it would have made him proud just to see what his son could do.

I get requests for the source code to M03 from time to time. The only working version of M03 that I have dates back to 2010 and was completed just prior to the birth of my oldest daughter, Dari. It's buggy and definitely just 'proof of concept'. I slapped it together as quickly as I could because I somehow managed to have the foresight to realize that I wasn't going to get a chance to work on it again for a long time once I had children - how correct I was!
Anyhow, I don't have the original source code available because the harddrive that contains it is in a shoebox on a shelf in my woodworking shop and covered in an inch of dust. I doubt it works and I never really concerned myself with the state of the harddrive since it was proof of concept work only and not worth preserving at all. So I never could provide M03 source code to any of the miriad of requests that I've had for it over the years.
But I've recently begun a clean rewrite of the algorithm and I have decided to shoot for the more advanced parsing that I had realized was possible when I first conceived of the algorithm long ago but which was too complicated to produce under time pressure back in 2010 when I last worked on the code. So the rewrite is a more advanced form of the algorithm and I'm dubbing the work 'M19'. (Perhaps I should be realistic am name it 'M27'?!!)
I had originally referred to the advanced context parsing technique as 'context skipping' since the technique is based on the idea that for approximately half of all contexts of order N - 1 there is no need to encode the transition to order N because the context boundaries of order N + 1 are available at the time. This certainly improves the speed of modelling all context boundaries during encoding and, I suspect, will improve the overall compression results as well (time will tell).
Anyhow, while the current state is *far* from a complete compressor I have pushed the full M19 context parser library to github and will update it as I have time to add the entropy coder to the context parser and, eventually, the entropy decoder to reverse the parsing and complete the coder.
This initial context parsing phase was actually extremely difficult to get correct and was a complete pain in the ass to work out. The resulting code might seem fairly trivial but that's only because I put in about 80 hours of work to refine it down and work out all of the issues. But I'm happy with the result. It works in 5N space, which was a very specific design requirement that I wasn't going to let go of. I want the encoder to be able to encode every context of the original input in the same amount of space as the BWT and this code acheives that. Plus it's reasonably fast for what it does. Parsing every context boundary for every context order of the original pre-BWT string using only the BWT string is no trivial task!
I was describing my old M99 algorithm to someone via email recently and decided to put together a working demo by a complete rewrite (the original code is lost on some broken drive in a shoebox somewhere and it's also over a decade old so it was time to re-write and document publicly - finally). The souce code is here on github.
M99 might be almost two decades old now but it's still very fast and efficient compared to more modern works. Plus it's a worthwhile alternative to Huffman in a lot of cases and achieves way better compression. I still believe that a specialized version designed for 8x8 DCT blocks would be very successful both in terms of encoding/decoding speed as well as overall compression. But that's a story for another day. Now I can get back to MSufsort 4 and also a clean re-write of M03 - if only there were enough time!
It took a lot longer than I wanted, although not long than I had anticipated, to produce a version of MSufSort which was fully parallel. There is still work to be done to make it worthy of 'Return of The King' status but I'm certainly happy that a lot of the road map has been achieved. There is a single component of MSufSort 4 remaining before the algorithm can clearly differentiate itself as best in class again. Specifically, induction sorting. This is a bit odd, really, considering that induced sorting is the single characteristic trait that every version of MSufSort has in common as a core algorithm. At it's heart the entire MSufSort family is a direct comparison, induced sort SACA. So, it is unexpected that it should be the only component of MSufSort 4 which remains on the road map.
The theoretical work has been done for a long time - how to do parallel induced sorting. But there are many variations to try out in practice and I'm not sure that I want to invest my time in that work at this point. I'm much more enthusiastic about Glimpse to be honest. It's not easy to decide that my personal project of a decade and a half is no longer a priority, but it just isn't. I guess it is true that with age comes wisdom. But I've come to realize that Glimpse has far more potential in the long term. It will become a product and not a project.
Anyhow, MSufSort 4/demo is posted on https://github.com/michaelmaniscalco/msufsort.
The chart below graphs the performance of MSufSort 4 on enwik8 using an increasing number of CPUs. The test machine has 4 physical cores. Using virtual cores (hyper threading) has very little effect on performance and so are not presented in the graph. The red line line represents the 'theoretical' best performance assuming that increasing the number of cores from 1 to N would result in an overall decrease in time required to compute the suffix array by a factor of N. The blue line represents the 'actual' performance of MSufSort 4. The chart demonstrates that MSufSort scales almost exactly at the theoretical best as the number of cores increases. I'm reasonably pleased with this performance.

Road map: (* indicates new for version 4)
- Three pivot multikey quicksort
- Insertion sort specialized for strings *
- Fully parallel quicksort/insertion sort
- Cache friendly improved two stage
- Tandem repeat sort
- Opportunistic induction sort *
- Fully parallel second stage for improved two stage *