


For those who are unfamiliar with M99 and M03 they are algorithms that I invented in 1999 and 2003 (which actually considered in 2000 but it took me three years to disclose the concept publicly) which are used to encode the Burrows/Wheeler Transform. M99 is highly effective as an alternative to traditional entropy coders when it comes to BWT output or any other 'run-ish' data with high speed (I suspect that it would be exceptionally effective at encoding DCT output and am working to demonstrate this when I have time). M03, in contrast is slower, although fast enough when compared to most compressors in its class, but is intended to encode the BWT specifically and does so using the contexts of the original pre-BWT string. It is the most effective (real world) BWT compression algorithm that I am aware of in spite of the fact that the existing prototype doesn't perform some of the more obvious and advanced modelling and encoding techniques - which I have not ever had time to complete. Both M99 and M03 reject the notion of any post-BWT secondary transform and are pure BWT->encode methods.
Anyhow, after producing the diagrams to illustrate M99 more clearly I had decided that it would be good to post them here as well. Maybe someone can invest the time needed to make a post-DCT version to improve jpg compression - or not.
The encoding technique for M99 is simply bit packing. Techniques which are superior to bit packing are used in the demo. For instance, range coding is used for the 'max' mode in the demo. But the cost for this slight improvement in compression is paid for by a noticable decrease in encode/decode speed which is what M99 has to offer in the first place. Another possible advantage for M99 is that it can be done in parallel (for the same block of data) which can greatly increase its encoding speed. Also, there is no need to pack any sort of encoding table with the data as there would be with Huffman, which is a *very* slight advantage for M99 in the generic usage case. M99 is *almost* as effective as Huffman for non BWT data, however, when the input contains localized and highly skewed symbol distributions (data with clusters of few symbols in long runs) it achieves compression that is as good as arithmetic coders yet it is only using simple bit packing. This is why it is so effective for BWT data.
Encoding for M99 is done by representing an integer value between 0 and N where N is the total frequency of a given symbol.
Bits are packed in a least significant bit first - most significant bit last fashion. This is because the MSB can often be inferred to be zero
once the less significant bits are known. For example to encode a value between 0 and 2 does not always require two bits (remember the bits are
packed in LSB to MSB fashion):
0 of 2 -> 00
1 of 2 -> 1
2 of 2 -> 01
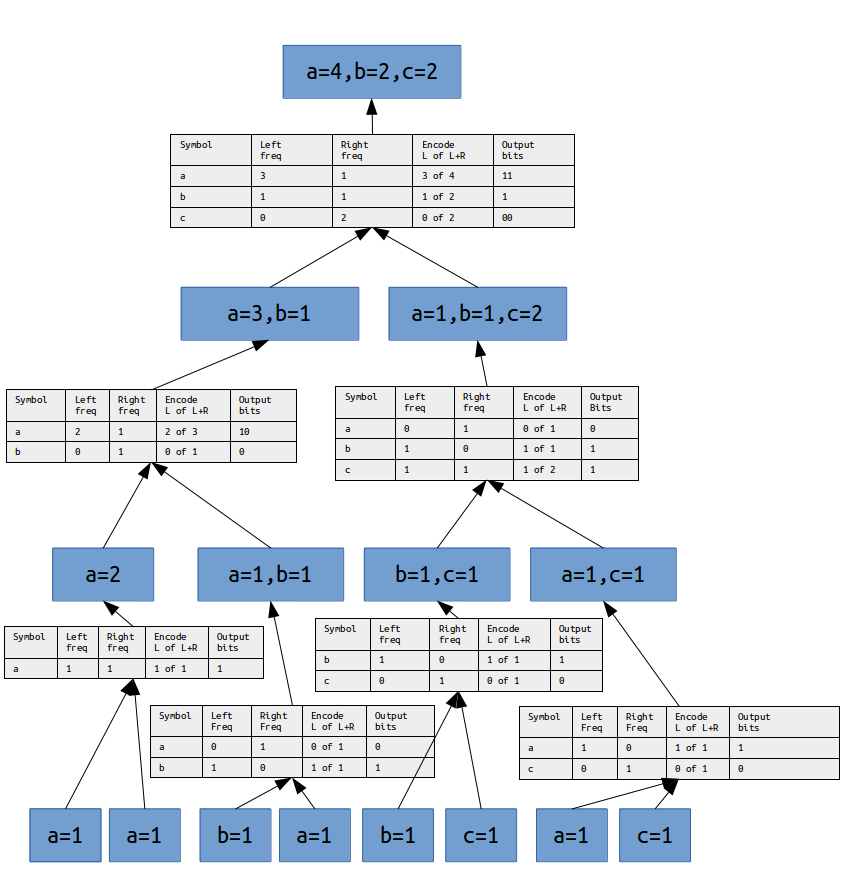
Encoding is done 'bottom-up' by consuming each byte of the input string as a vector containing a single symbol with a frequency count of 1. Each of the these neighboring vectors are 'merged' into a 'parent' vector which contains each of the unique symbols of the 'child' vectors and each of the symbols in the parent defines the frequency of each of its symbols as the sum of the frequence of that symbol from the two child vectors. Encoding is done to generate the neseccary information to 'divide' the parent vector back into the original two 'child' vectors. The encoding process repeats until all child vectors have been merged into a single parent vector which contains each of the unique input symbols with a frequency which is equal to the number of occurences of that symbol in the orignal input. Decoding is the reverse process - 'dividing' each parent vector into its original 'child' vectors repeatedly until each child vector contains a single symbol of frequency 1. At this point the order of the child vectors describes the original input.
Also, for sake of clarity, the examples in the diargram are not optimal. Often, during encoding some of the values to encode can be partially, or in some cases completely, inferred and no encoding is necessary. This is because the 'child' and 'parent' total frequencies are completely inferred by both the encoder and the decoder. I'll clarify this in a follow up post when I get the chance.
Finally, M99 is the predecessor to M03 and if you understand M99 clearly enough you might just be able to re-invent M03 yourself before I get the chance to post a follow up post on that as well. Hint: why not encode from top-down?
M99 encoding the string 'aababcac':
M99 decoding the string 'aababcac':

I don't feel it is necessary to spell out why I believe that any attempt to censor another's free speech is wrong. Instead I will offer this, a quote from HackerNews user 'sirfz' who claims to be one of the engineers working on this project. Approximately 86 days prior to the date of this post, on a different thread, this person posted the following:
"This should certainly be adopted by official/serious projects (such as albums, movies, events, etc.) with Arabic names written in Latin script. The use of the "chat" form (e.g. "7" for "Ø" and "3" for "ع") is just horrid and makes any serious work look childish."
The content of the dialog is of no consequence. What is important is that the Sherloq tool rated this quote as 93% "hatefulness:"

To each of us I then ask - What shall we do with 'sirfz'? Shall we alter the definition of "hatefulness" or shall we censor his speech?

template <std::size_t N>
class const_char_array_wrapper
{
public:
const_char_array_wrapper
(
char const (&value)[N]
):
value_(value)
{
}
char const
(
& get_value() const
)[N]
{
return value_;
}
// or, for implicit conversions
(
& operator char const () const
)[N]
{
return value_;
}
private:
char const (&value_)[N];
};